High Performance Computing — HPC
Objectives
Let’s recap and go a little further into the UPPMAX hardware!
See also
Instructor note
Approx timing: 11.35-11:40
Information
HPC, HTC and MTC
The Buzz word is HPC or High Performance Computing, but this is rather narrow focusing on fast calculation, i.e. processors and parallelism
Many of your projects are more focusing on high throughput, large memory demands and many tasks.
Here is a list of the three most common Computing paradigms:
HPC: High Performance Computing — Focus on floating point operations per second (FLOPS, flops or flop/s)
characterized as needing large amounts of computing power for short periods of time
HTC: High-Throughput Computing —
operations or jobs per month or per year.
more interested in how many jobs can be completed over a long period of time instead of how fast.
independent, sequential jobs that can be individually scheduled o
MTC: Many-task Computing — emphasis of using many computing resources over short periods of time to accomplish many computational tasks
bridge the gap between HTC and HPC.
reminiscent of HTC, but including both dependent and independent tasks), where the primary metrics are measured in seconds (e.g. FLOPS, tasks/s, MB/s I/O rates), as opposed to operations (e.g. jobs) per month.
high-performance computations comprising multiple distinct activities, coupled via file system operations.
What is a cluster?
A network of computers, each computer working as a node.
From small scale RaspberryPi cluster…

To supercomputers like Rackham.

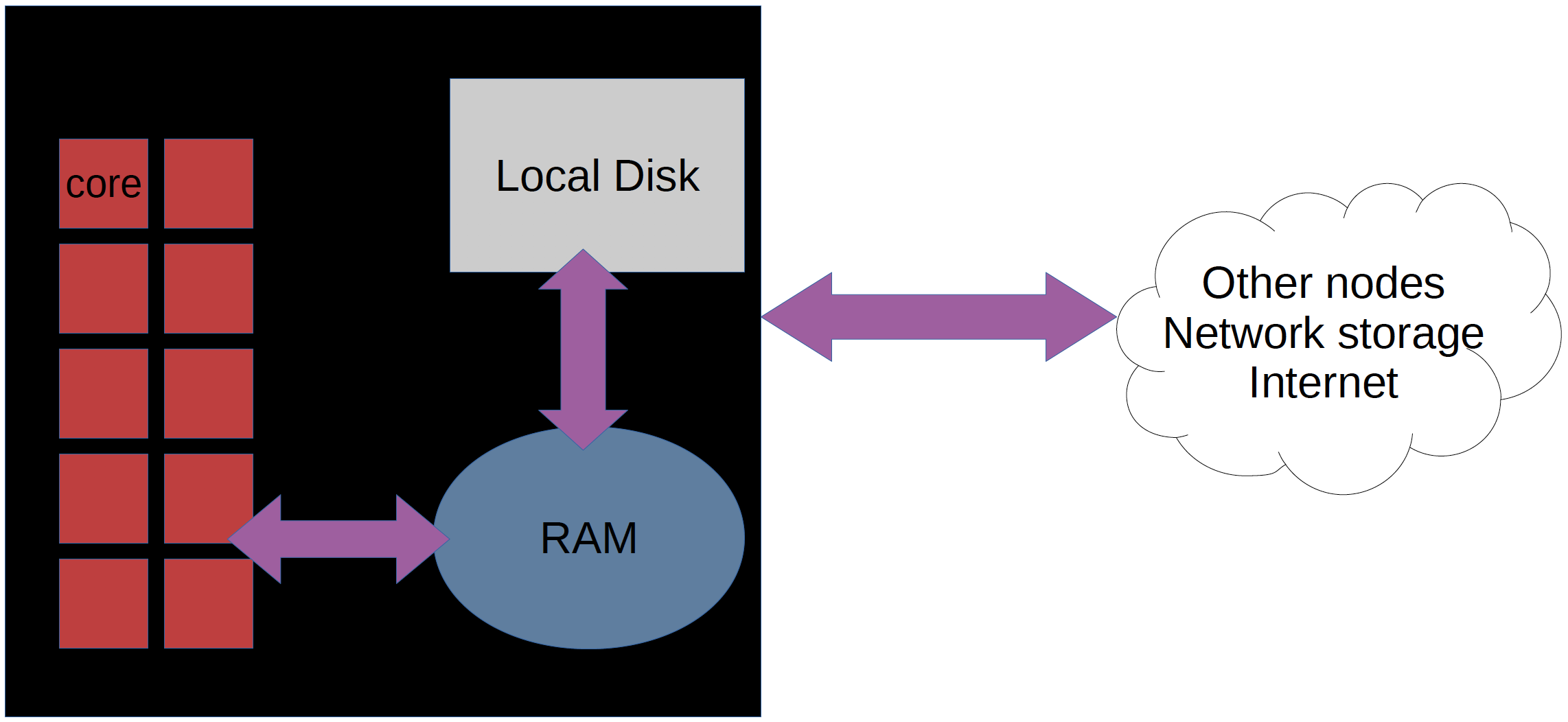
Each node contains several processor cores and RAM and a local disk called scratch.
The user logs in to login nodes via Internet through ssh or Thinlinc.
Here the file management and lighter data analysis can be performed.
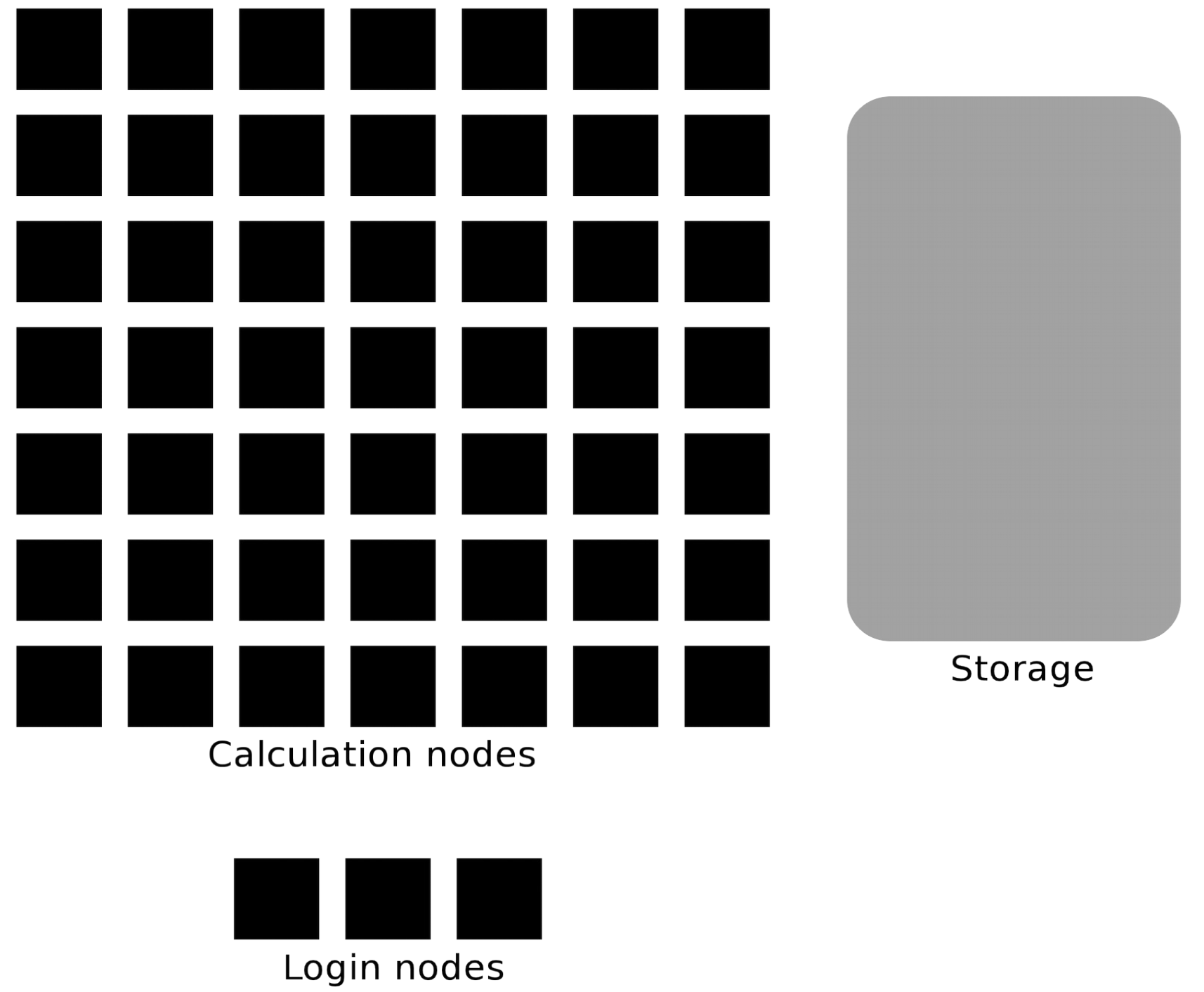

The calculation nodes has to be used for intense computing.
“Normal” softwares use one core.
Parallelized software can utilize several cores or even several nodes. Keywords signalizing this are e.g.:
“multi-threaded”, “MPI”, “distributed memory”, “openMP”, “shared memory”.
To let your software run on the calculation nodes
start an “interactive session” or
“submit a batch job”.
More about this in today’s introduction to jobs.
Storage basics
All nodes can access:
Your home directory on Domus or Castor
Your project directories on Crex or Castor
Its own local scratch disk (2-3 TB)
If you’re reading/writing a file once, use a directory on Crex or Castor
If you’re reading/writing a file many times…
Copy the file to ”scratch”, the node local disk:
cp myFile $SNIC_TMP
The UPPMAX hardware
Clusters
We have a number of compute clusters:
Rackham , reserved for SNIC projects
Snowy, GPU, long jobs reserved for UPPMAX projects and Education
Bianca , a part of SNIC-SENS
Miarka, reserved for Scilifelab production
UPPMAX cloud, a part of SNIC Science Cloud
The storage systems we have provide a total volume of about 25 PB, the equivalent of 50,000 years of 128-bit encoded music. Read more on the storage systems page.
UPPMAX storage system names (projects & home directories)
Rackham storage: Crex & Domus
Bianca storage: Castor & Cygnus
NGI production system (Miarka): Vulpes
NGI delivery server: Grus
Off-load storage: Lutra
System usage
More about the systems can be found at the System resources page
A little bit more about Snowy
-
There is a local compute round for UU users applying for Snowy in SUPR.
GU (courses) applications (including GU GPU usage) are not done in SUPR, but are supposed to be routed through the service desk.
The details can be found at the Getting started page.
About Bianca?
Wait for it!
Keypoints
UPPMAX has several clusters
each having its focus and limitation or possibilites
access is determined by type of project