LLM and hardware
Neural networks

- Learn patterns by adjusting parameters (weights);
- Training = prediction → differentiation → update;
- So far: mini-batch & optimizer & big → good.
Attention mechanism
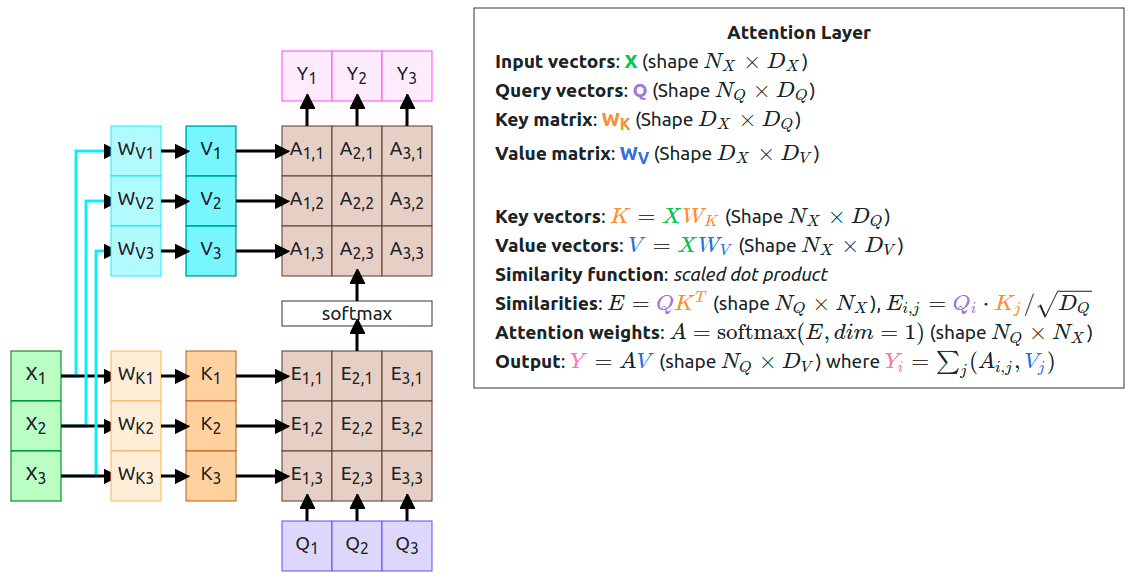
Image source: Introduction
to Attention Mechanism
- keys, queries, and vales (K,Q,V);
- general ways of building trainable “relations” from neural networks;
- self-attention.
Transformer vs. RNN
![]()
- Transformer computes relationships between tokens (attention);
- tokens can be processed in parallel
Training of LLMs

- Just neural networkes that can be parallelized more efficiently;
Fine-tuninig of LLMs

- With specialized data (instruct, chat, etc);
- Less memory usage by “freezing parameters”;
- LoRA: low-rank adapters (arXiv:2106.09685).
Inference of LLMs

- GPT-style inference: pre-filling and decoding;
- Pre-filling: process the input prompt in parallel;
- Decoding: generate new tokens one-by-one, using cached results.
Optimize caches for inference

- Optimizing access to KV cache:
- paged attention: indexed blocks of caches;
- flash attention: fuse operations to reduce caches;
HPC clusters

- Racked computer nodes;
- Parallel network storage;
- Infiniband/RoCE networking;
Alvis hardware - network & storage

- Infiniband: 100Gbit (A100 nodes);
- Ethernet: 25Gbit (most other nodes);
- Fast storage: WEKA file system.
Tools to gather information

- grafana (network utilization, temp disk);
- nvtop, htop (CPU/GPU utilization, power draw);
- nvidia nsight (advanced debugging and tracing);
Find details in C3SE documentation.
If you are surprised that models work better with more variables, you are not alone; see double descent.↩︎
arXiv:2106.09685 [cs.CL]↩︎